
近日,讯飞星火大模型V3.5(以下简称“讯飞星火”)春季上新。面向用户高效准确知识获取的痛点,科大讯飞发布业界首个长文本、长图文、长语音大模型,不仅能够把各种信息来源的海量文本、图文资料、会议录音等进行快速学习,还能够在各种行业场景给出专业、准确回答。
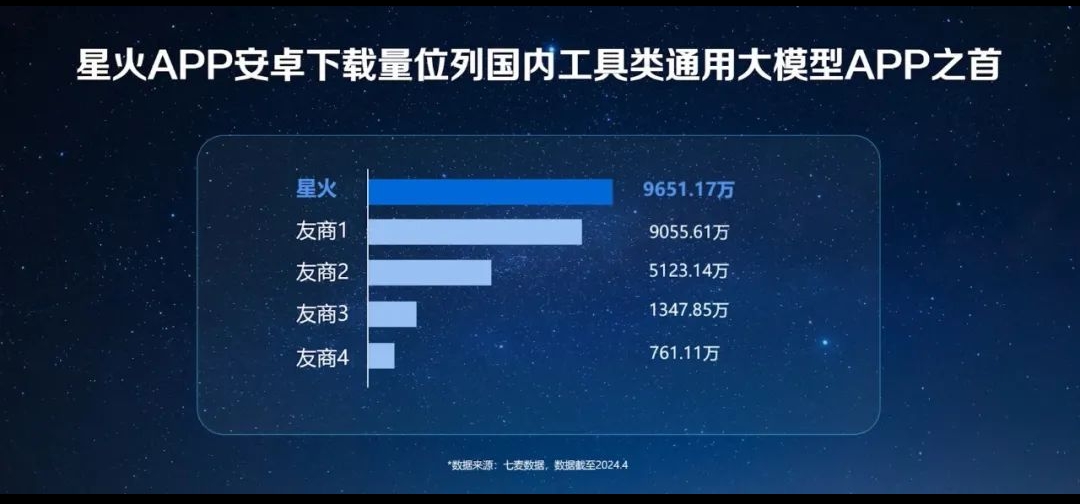
科大讯飞进一步升级星火语音大模型,首发多情感超拟人合成,具备情绪表达能力,并推出一句话声音复刻功能,让科技更有温度。同时,面向企业应用场景,科大讯飞推出星火智能体平台,帮助企业解决大模型落地的最后一公里难题。据七麦数据显示,讯飞星火APP在安卓端的下载量已经超过9600万次,在国内工具类通用大模型APP中排名第一。
为什么要做长文本、长图文、长语音的大模型?
分析发现,在知识获取和学习的过程中,广大用户能拿到的资料往往不仅是现成的长文本,还有随手可见的报刊书籍内容、各种研讨会的PPT内容,老师黑板上的板书、同学的笔记,以及各种会议录音、访谈,各种网上的发布会、培训教育视频等,能不能把这些文本、图片、语音等都上传到讯飞星火中,快速地获取知识?
为此,科大讯飞推出首个支持长文本、长图文、长语音的大模型,来解决用户真实场景中多源信息的获取需求。
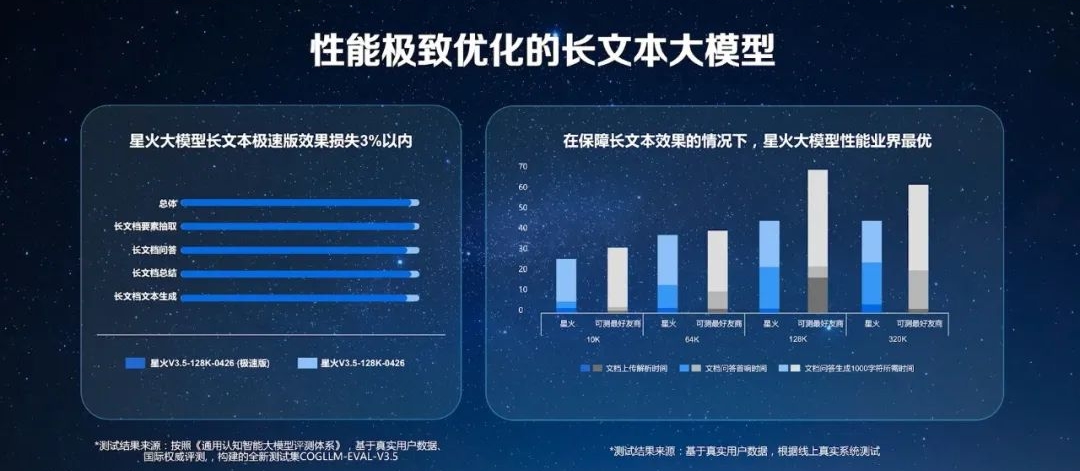
据了解,本次讯飞星火长文本功能全新升级后,具备长文档信息抽取、长文档知识问答、长文档归纳总结、长文档文本生成等能力,总体已经达到GPT-4 Turbo 4月最新长文本版本的97%水平,而在银行、保险、汽车、电力等多个垂直领域的知识问答任务上,讯飞星火长文本总体水平已经超过GPT-4 Turbo。
长文本功能的落地需要解决信息高效处理的问题:面对上百万甚至上千万文字,长文本大模型消耗的运算资源非常大。
为了解决大模型应用效率和准确率问题,刘庆峰谈道,基于讯飞星火V3.5对长文本的理解、学习、回答能力,科大讯飞进行了重要的模型剪枝和蒸馏,从而推出业界性能最优的130亿参数的大模型,在效果损失仅3%以内的情况下,使得星火在文档上传解析处理、知识问答的首响时间以及文字生成方面都获得了极大的效率提升。测试显示,在保障长文本效果的情况下,无论是10K、64K、128K token,还是更长的文本上,星火大模型的性能都做到业界最优。
面向复杂的图文场景,科大讯飞在图文识别、公式识别大赛多年国际第一的技术积累基础上,首次推出星火图文识别大模型。
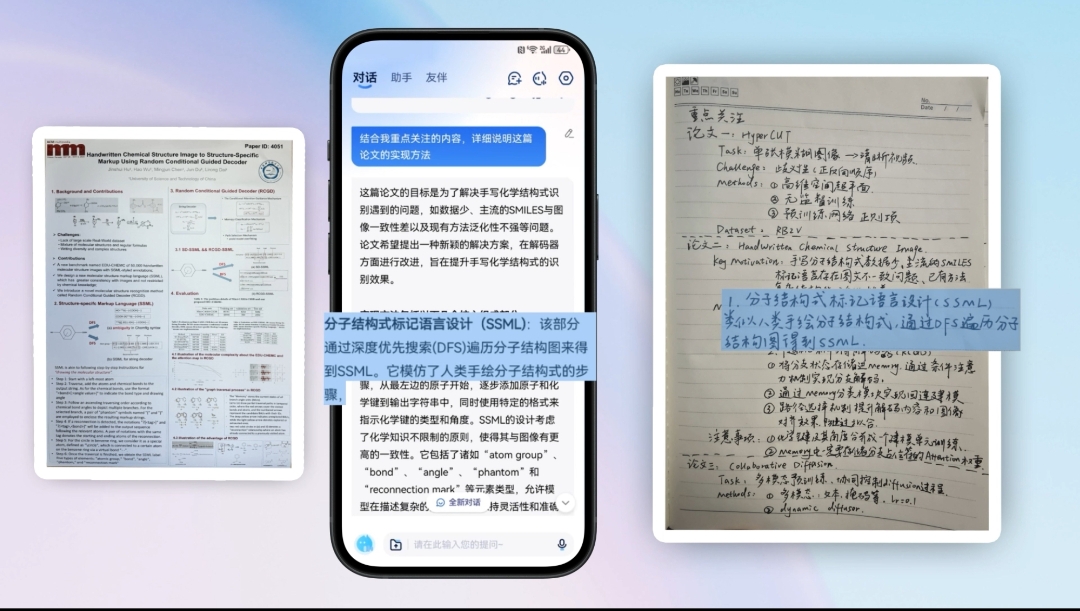
相比传统小模型逐行文字识别的限制,星火图文识别大模型具有三大优势:1)能够直接处理非常复杂的版面分析,目前已经覆盖31个典型场景,比如书刊、学术论文、专利、报纸、海报、PPT等,同时能自动识别标注出18类不同的版面要素,比如页眉、页脚、标题、段落、表格、公式、印章、手写等;2)融合篇章上下文语义进行文字识别,识别更精准;3)面向教育、金融、医疗、科研等专业领域深度优化,能自动实现更多领域的专业符号识别。
根据国际公开的权威英文测试集来看,讯飞星火的图文识别效果超过微软和谷歌。从典型应用场景来看,在科研、金融以及企业产品技术文档等识别效果都处于业界领先地位。
此外,面对广泛的音视频信息高效获取需求,科大讯飞也推出长语音功能,将国际领先的语音识别和翻译技术结合起来,可以实现会议录音、学习视频等的一键研读,实现音视频场景的高效知识获取。
此外,据刘庆峰透露,科大讯飞将在6月27日发布讯飞星火大模型V4.0,进一步解放生产力、释放想象力。